OPINION
Notes sur les parallélismes du pré-entraînement et les runs d'entraînement ratés
Dwarkesh Patel décortique pourquoi les runs de pré-entraînement échouent, entre causalité brisée et biais introduits dans les architectures MoE.
Dwarkesh Patel·Dwarkesh Patel·16 mai 2026
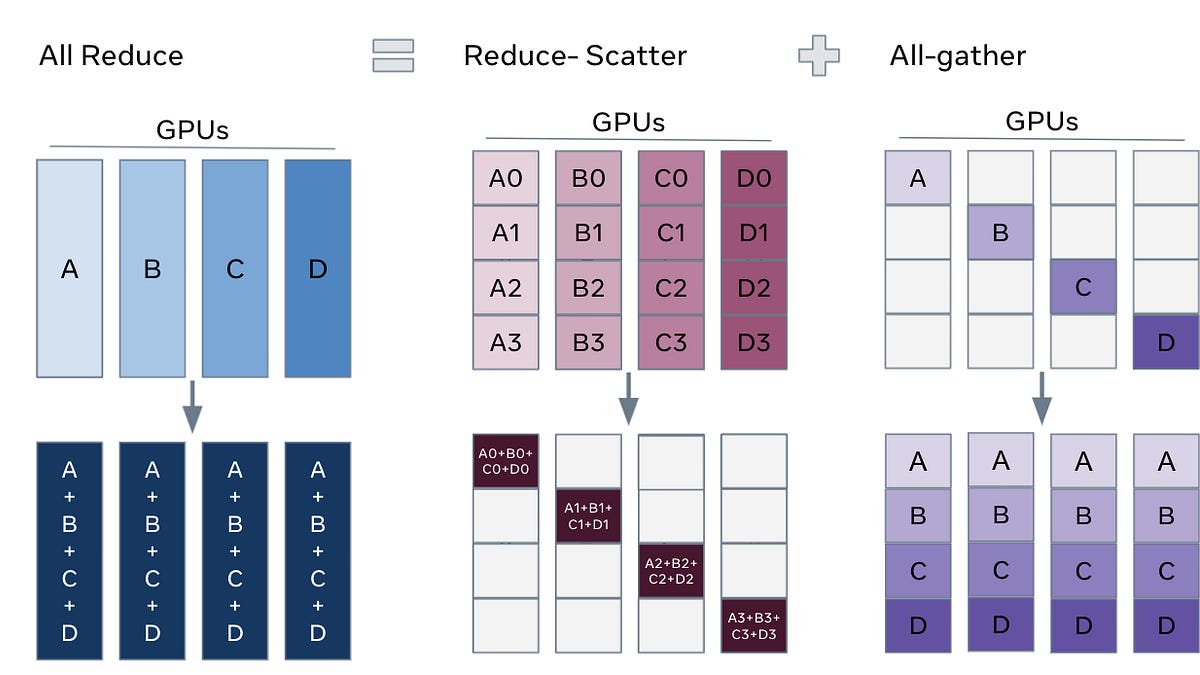
Image · Source originale
Patel analyse les causes profondes d'échec des runs de pré-entraînement, en particulier dans les architectures MoE. Le routage par choix d'expert (expert choice) améliore l'équilibrage de charge mais brise la causalité : l'allocation d'un token peut dépendre de tokens futurs, introduisant une fuite d'information entre entraînement et inférence. Une rumeur attribue les performances décevantes de Llama 4 à ce problème.
Chaleur 0
Pertinence 72
Nouveauté 55