RECHERCHE
TIPSv2 : améliorer le pré-entraînement vision-langage par un meilleur alignement patch-texte
Google DeepMind présente TIPSv2, une méthode de pré-entraînement multimodal qui renforce l'alignement entre patches visuels et tokens textuels.
Hacker News (filtré IA)·@gmays·24 avril 2026
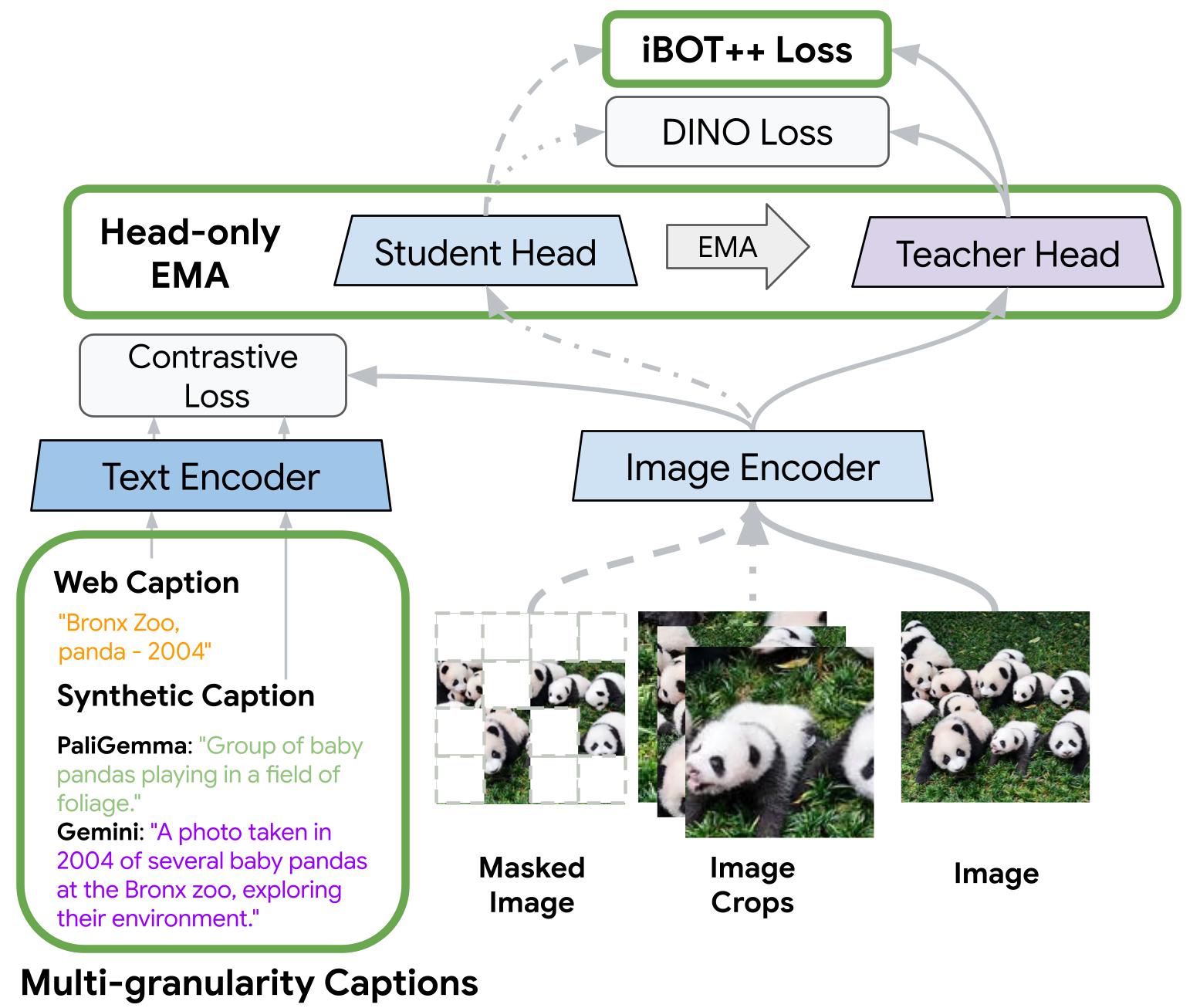
TIPSv2 est une approche de pré-entraînement vision-langage développée par Google DeepMind, qui améliore l'alignement entre les régions locales d'une image (patches) et les tokens textuels correspondants. La méthode vise à produire des représentations visuelles plus fines et mieux ancrées dans le langage, avec des gains mesurables sur plusieurs benchmarks multimodaux.
Chaleur 0
Pertinence 72
Nouveauté 65